
April 2026 will go down as the most competitive month in frontier AI history. OpenAI shipped GPT-5.5 (codename “Spud”) on April 23, exactly one week after Anthropic released Claude Opus 4.7 on April 16. Google DeepMind’s Gemini 3.1 Pro, available since February 19, rounds out a three-way race where no single model dominates across every benchmark. For teams building production AI systems, the question is no longer “which model is best?” but rather “which model is best for this specific workload?” This guide breaks down where each model leads, where it falls behind, and how to route tasks accordingly.
Release context: three labs, three bets
GPT-5.5 is the first fully retrained base model from OpenAI since GPT-4.5. Every release between them (5.1 through 5.4) was a post-training iteration on the same foundation. GPT-5.5 is a ground-up rebuild, which explains the larger benchmark jumps compared to typical point releases. It is natively omnimodal, processing text, images, audio, and video through a single unified architecture.
Claude Opus 4.7 focuses on a different target. Anthropic pushed SWE-bench Pro from 53.4% (Opus 4.6) to 64.3%, introduced the xhigh effort level, and added high-resolution vision up to 3.75 megapixels. It also launched alongside Claude Design, a visual collaboration product. The model emphasizes self-verification and instruction precision over autonomous tool orchestration.
Gemini 3.1 Pro, released February 19, 2026, is the value play. At $2 per million input tokens and $12 per million output tokens, it costs 60% less than GPT-5.5 on output while delivering competitive reasoning. It scores 77.1% on ARC-AGI-2 (more than double Gemini 3 Pro), 94.3% on GPQA Diamond, and offers a 1M token context window with native SVG and 3D code rendering.
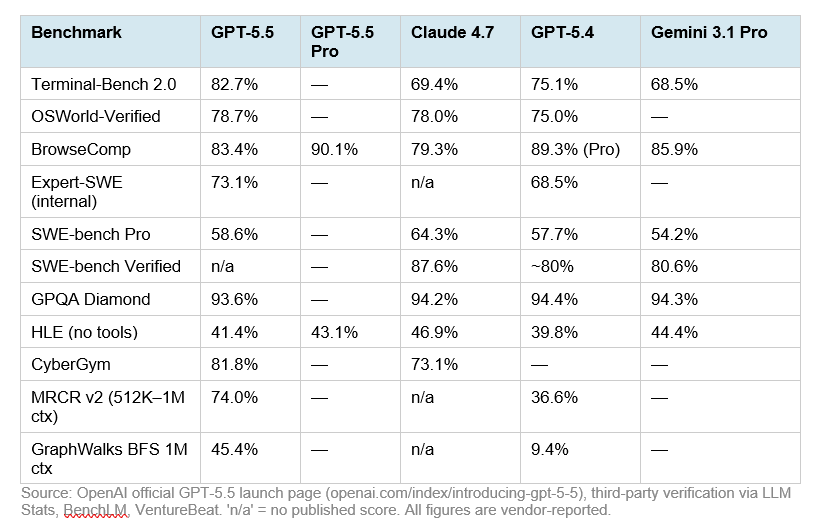
Head-to-head benchmarks
On the 10 shared benchmarks reported by both providers, Claude Opus 4.7 leads on 6 and GPT-5.5 leads on 4. But the margins cluster by category. GPT-5.5 dominates in planning-and-execution tasks. Opus 4.7 dominates in codebase-resolution and reasoning-heavy evaluations. Gemini 3.1 Pro holds the cost-efficiency crown while remaining competitive on quality.
| Benchmark | GPT-5.5 | Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Pro | 58.6% | 64.3% | 54.2% |
| Terminal-Bench 2.0 | 82.7% | 69.4% | 68.5% |
| GPQA Diamond | 93.6% | 94.2% | 94.3% |
| OSWorld-Verified | 78.7% | 78.0% | — |
| BrowseComp | 84.4% | 79.3% | 85.9% |
| MCP Atlas | 75.3% | 77.3% | 69.2% |
| FinanceAgent v1.1 | 60.0% | 64.4% | 59.7% |
| CyberGym | 81.8% | 73.1% | — |
| HLE (no tools) | 41.4% | 46.9% | 44.4% |
Sources: OpenAI official announcement (April 23, 2026), Anthropic official announcement (April 16, 2026), Google DeepMind model card (February 2026). All scores are self-reported at each provider’s high reasoning tier.
Pricing and cost per task
| Model | Input / 1M | Output / 1M | Context |
|---|---|---|---|
| GPT-5.5 | $5.00 | $30.00 | 1M tokens |
| Claude Opus 4.7 | $5.00 | $25.00 | 1M tokens |
| Gemini 3.1 Pro | $2.00 | $12.00 | 1M tokens |
Input pricing is identical between GPT-5.5 and Opus 4.7 at $5 per million tokens. Opus 4.7 is 17% cheaper on output at $25 versus $30. However, Opus 4.7 doubles its pricing above 200K-token prompts ($10/$37.50), while GPT-5.5 holds flat. OpenAI also claims GPT-5.5 uses roughly 40% fewer tokens to complete the same Codex task as GPT-5.4, which means the effective cost-per-task increase is closer to 20% despite the 2x sticker-price jump. Gemini 3.1 Pro sits at a dramatically lower price point, roughly 60% less than GPT-5.5 on output, making it the clear choice for high-volume workloads where its capability envelope is sufficient.
Where each model wins
The pattern across benchmarks is consistent. GPT-5.5 leads on autonomous planning and execution: Terminal-Bench 2.0 (+13 points over Opus), OSWorld computer use, CyberGym, and long-context retrieval (MRCR v2 nearly doubled from 36.6% to 74.0%). It also scores 84.9% on GDPval for knowledge-work tasks across 44 occupations. For DevOps automation, terminal-driven workflows, and cross-functional agent tasks, GPT-5.5 is the right default.
Opus 4.7 leads where precision matters more than autonomy. Its 64.3% on SWE-bench Pro means it resolves more real-world GitHub issues end-to-end than any other generally available model. The self-verification behavior (plan, execute, verify, report) produces fewer broken pull requests. Its sub-second time-to-first-token (~0.5s versus GPT-5.5’s ~3s) makes it the better pick for interactive IDE integrations and chat surfaces. The 3.75-megapixel high-resolution vision also makes it unmatched for dense screenshots, financial charts, and detailed document analysis.
Gemini 3.1 Pro wins on two axes: cost-efficiency and specialized capabilities. Its 77.1% on ARC-AGI-2 abstract reasoning is best-in-class. BrowseComp performance at 85.9% surpasses both competitors for autonomous web research. At $2/$12 per million tokens, it delivers roughly 80-90% of frontier performance at 40% of the cost. For document processing pipelines, high-volume classification, and long-context analysis where cost-per-completion matters, Gemini 3.1 Pro is difficult to beat.
Practical routing strategy for SMBs
The smartest production systems do not pick one model. They route tasks to the model best suited for each workload. Based on the benchmark data and real-world reports from early adopters, here is a practical multi-model routing architecture:
- GPT-5.5 (30% of traffic) — Agentic workflows, terminal automation, computer use, DevOps pipelines, cross-functional knowledge work, document generation
- Claude Opus 4.7 (30% of traffic) — Complex multi-file code fixes, code review, architecture decisions, high-resolution image analysis, IDE-integrated coding, any task reviewed by a human
- Gemini 3.1 Pro (25% of traffic) — High-volume classification, summarization, web research, long-context document processing, cost-sensitive batch operations
- Budget models (15% of traffic) — Simple queries, formatting, extraction — route to GPT-5.4 mini ($0.75/M input) or Claude Haiku 4.5 ($0.80/M input)
This approach typically reduces total spend by 40-60% compared to routing everything to a single frontier model, while maintaining or improving output quality. Both GPT-5.5 and Opus 4.7 offer batch and flex pricing at 50% off standard rates, which is the single biggest cost lever for high-volume production use.
One caution worth noting: GPT-5.5 hits an 86% hallucination rate on the third-party AA-Omniscience benchmark despite achieving the highest recorded accuracy at 57%. If your workflows have high hallucination costs — legal, medical, financial compliance — test GPT-5.5 thoroughly against Opus 4.7 (36% hallucination rate) or Gemini 3.1 Pro (50%) before committing to it as a default.
Key takeaways
- No single model wins everywhere. GPT-5.5 leads on agentic execution (+13 points on Terminal-Bench). Opus 4.7 leads on codebase resolution (+5.7 points on SWE-bench Pro). Gemini 3.1 Pro leads on cost-efficiency and abstract reasoning.
- Price does not equal cost. GPT-5.5’s 40% token-efficiency gain means its effective cost-per-task is far lower than its per-token price suggests. Opus 4.7’s 200K+ surcharge can flip the economics for long-context workloads.
- Latency matters for interactive use. Opus 4.7’s sub-second TTFT makes it the clear winner for chat and IDE integrations. GPT-5.5’s slower start matters less for autonomous background tasks.
- Multi-model routing is the production standard. Match each task to the model optimized for it, and route simple tasks to budget-tier models to control costs.
The frontier model landscape in April 2026 rewards specificity. Teams that benchmark models against their own real workflows, rather than relying on marketing benchmarks, will make better decisions and spend less. For SMBs building automation stacks with tools like n8n, the practical path forward is clear: test all three against your actual tasks, then build a routing layer that sends each job to the model that handles it best.



[…] days. That is the gap between GPT-5.5, which shipped on March 5, 2026, and GPT-5.5, which dropped on April 23. It is the shortest interval between frontier model releases in […]
[…] release of GPT-5.5 on April 23, 2026, has sent shockwaves through the enterprise AI landscape. While the model […]
[…] reports across scattered tools to re-entering data from one system into another. OpenAI’s GPT-5.5, released on April 23, 2026, changes what’s realistically automatable for companies that […]
[…] has shifted from rigid, linear sequences to autonomous, decision-making agents. The release of OpenAI’s GPT-5.5 (codenamed “Spud”) on April 23, 2026, has provided the final technical piece of the […]