The memory bottleneck in large language model (LLM) inference reached a critical inflection point in 2026. As context windows expanded to millions of tokens and multimodal applications became the norm, the KV cache—simultaneously the engine of transformer efficiency and the Achilles’ heel of GPU memory consumption—demanded fundamentally new compression approaches. Two parallel breakthroughs emerged at ICLR 2026 to address this challenge: Google’s TurboQuant and NVIDIA’s KVTC. Each offers a radically different philosophy for compressing the key-value cache, and understanding their tradeoffs is essential for organizations architecting production LLM systems.
Understanding the KV cache compression problem
Before diving into the comparative analysis, understanding whyKV cache compression matters illuminates the stakes. During transformer inference, the KV cache stores precomputed key and value vectors from previous tokens. This prevents redundant recalculation of attention scores—a 70B parameter model processing a 128K context window can require over 80GB of KV cache memory alone.
Traditional quantization methods like 8-bit or 4-bit compression reduce memory but carry hidden costs: quantization constants must be stored per block, adding 1–2 bits of overhead. For small business and enterprise deployments, this translates directly into hardware expenses. A deployment requiring four H100 GPUs might drop to two with effective compression—potentially $50,000+ in infrastructure savings.
TurboQuant: Google’s vector quantization approach
TurboQuant, announced March 24, 2026, represents Google’s research contribution to solving this bottleneck. Published as arXiv:2504.19874 and accepted to ICLR 2026, TurboQuant achieves 6x compression at 3-bit precision with provably zero accuracy loss on standard benchmarks.
Technical approach
TurboQuant combines two algorithms in a two-stage pipeline:
- PolarQuant: Randomly rotates data vectors to simplify geometry, converting standard Cartesian coordinates into polar coordinates (radius + angle). This eliminates the expensive normalization step and removes per-block quantization constants.
- QJL (Quantized Johnson-Lindenstrauss): Uses just 1 bit per value to capture residual error from the first stage. The Johnson-Lindenstrauss Transform preserves distances while reducing dimensionality.
The result is a training-free algorithm requiring no calibration data. TurboQuant operates in an online per-token fashion, making it suitable for streaming applications.
Performance benchmarks
Google’s evaluation across LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval demonstrated:
| Metric | TurboQuant (4-bit) | TurboQuant (3-bit) | Baseline (FP32) |
|---|---|---|---|
| Compression Ratio | 4x | 6x | 1x |
| Accuracy Loss | Near-zero | Near-zero | N/A |
| Attention Speedup (H100) | Up to 8x | Up to 8x | Baseline |
| Calibration Required | No | No | N/A |
KVTC: NVIDIA’s transform coding methodology
NVIDIA’s KVTC (KV Cache Transform Coding), published as arXiv:2511.01815 and also accepted to ICLR 2026, takes a fundamentally different approach inspired by classical media compression like JPEG. KVTC achieves up to 20x compression with less than 1 percentage point accuracy degradation.
Technical approach
KVTC combines three techniques in a pipeline resembling transform coding in image compression:
- PCA-based feature decorrelation: Principal Component Analysis transforms the KV representation to concentrate energy into fewer dimensions, similar to how JPEG uses discrete cosine transform.
- Adaptive quantization: Dynamically assigns bit-width based on feature importance rather than uniform bit allocation.
- Entropy coding: Further reduces size through statistical compression, analogous to JPEG’s Huffman coding stage.
This approach requires a brief initial calibration (approximately 10 minutes per model) but leaves model parameters unchanged, enabling application to any pretrained model without retraining.
Performance benchmarks
NVIDIA evaluated KVTC on Llama 3, Mistral NeMo, and R1-Qwen 2.5 across AIME25, GSM8K, LiveCodeBench, LongBench, MATH-500, MMLU, Qasper, and RULER benchmarks:
| Metric | KVTC | Baseline Methods |
|---|---|---|
| Compression Ratio | Up to 20x (40x+ specific cases) | 4–5x (KIVI, H2O, TOVA) |
| Accuracy Degradation | < 1 percentage point | Varies; degrades beyond ~5x |
| TTFT Speedup | Up to 8x | Baseline |
| Calibration Required | ~10 minutes once per model | Varies |
| Tested Model Sizes | 1.5B – 70B parameters | Typically smaller ranges |
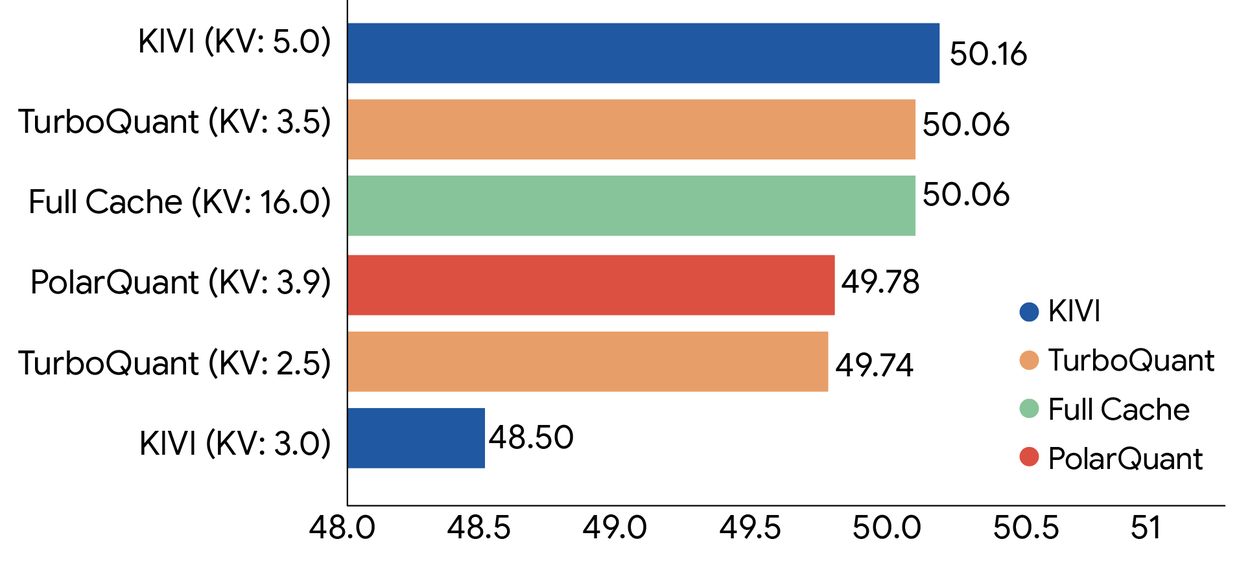
Head-to-head comparison: TurboQuant vs KVTC
The simultaneous presentation of these competing approaches at ICLR 2026 highlights the rapid innovation in KV cache optimization. Here’s how they compare across critical dimensions:
| Dimension | TurboQuant | KVTC |
|---|---|---|
| Maximum Compression | 6x (4–6x typical range) | 20x (40x+ specific cases) |
| Accuracy Loss | Zero (theoretically guaranteed) | < 1 percentage point |
| Core Technique | Vector quantization with Hadamard rotation | Transform coding (PCA + entropy) |
| Calibration Required | No calibration needed | ~10 minutes initial calibration |
| Online Operation | Per-token, streaming-friendly | Block-wise, batch-oriented |
| Best Use Case | Zero-config deployment, real-time apps | Maximum compression for batch serving |
| Model Size Testing | Up to ~8B parameters published | 1.5B – 70B parameters tested |
| Overhead | Negligible runtime overhead | PCA computation, entropy coding |
When to choose each method
The divergence in architectural philosophy creates distinct optimization profiles. Understanding these helps SMBs and enterprise teams make the right technical decision.
Choose TurboQuant when:
- Zero accuracy loss is non-negotiable: Medical, financial, or legal applications where any degradation is unacceptable
- No calibration overhead: Quick deployment across multiple models without per-model tuning
- Streaming/real-time inference: Conversational agents requiring per-token processing without batching
- Simpler integration: Already implemented in vLLM with –kv-cache-dtype option (PR #38280)
- Smaller models: Optimized for deployments under 10B parameters
Choose KVTC when:
- Maximum compression is the priority: Deploying 70B models on consumer-grade hardware or maximizing batch size
- Long context workloads: Processing millions of tokens where KV cache dominates memory
- Batch inference optimization: Chat completion APIs and document processing pipelines
- Multi-turn conversation caching: Reusable caches across shared-prefix prompts common in chat applications
- Hardware cost reduction: Trading minimal accuracy loss for 3x additional memory savings over TurboQuant
Practical implementation considerations
Both methods have progressed from research papers to production-ready implementations. NVIDIA’s KVTC is available through community implementations on GitHub, while Google’s TurboQuant has been integrated directly into vLLM, the popular inference engine used by many production deployments.
Integration status (April 2026)
| Platform | TurboQuant Support | KVTC Support |
|---|---|---|
| vLLM | Integrated (PR #38280) | Community implementations |
| llama.cpp | Discussion #20969 (in progress) | Community ports |
| HuggingFace Transformers | Via custom integration | Via custom integration |
| TensorRT-LLM | Planned | NVIDIA native expected |
Impact on hardware economics
For SMBs evaluating these technologies, the financial implications are substantial. An example deployment scenario:
Scenario: Deploying a Llama 3.1 70B model with 128K context window for customer support
Either compression method enables significant infrastructure savings. The choice between them depends on whether the organization prioritizes absolute accuracy (TurboQuant) or maximum resource efficiency (KVTC).
Looking forward: The convergence question
The emergence of two fundamentally different approaches at the same conference raises an interesting question: will these methods remain distinct alternatives, or will hybrid approaches emerge? The complementary nature of vector quantization (TurboQuant’s strength in per-token processing) and transform coding (KVTC’s batch optimization) suggests future systems might combine both—using TurboQuant for real-time streaming heads while compressing completed contexts with KVTC for storage.
NVIDIA’s demonstrated results on models up to 70B parameters versus TurboQuant’s focus on smaller models also suggests a segmentation: KVTC may dominate enterprise-scale deployments while TurboQuant finds its home in edge and consumer applications demanding zero-config deployment.
Bottom line for decision makers
For technical teams making KV cache compression decisions in April 2026:
- Start with TurboQuant if you need immediate deployment with guaranteed accuracy and minimal operational complexity
- Invest in KVTC if you’re optimizing for maximum throughput on expensive GPU infrastructure and can accept sub-1% accuracy tradeoffs
- Monitor both: The field is evolving rapidly, with community implementations closing integration gaps monthly
The real winner from this competition is the broader LLM deployment ecosystem. With two robust approaches now available, organizations previously priced out of long-context inference now have viable paths to deployment.


Leave a Comment
Sign in to join the discussion and share your thoughts.
Login to Comment