Anthropic’s rapid release cadence can make even seasoned teams ask: should we really upgrade again? As of November 24, 2025, Claude Opus 4.1 and the newly released Claude Opus 4.5 are both available across the Claude API, Amazon Bedrock, and Google Vertex AI. Opus 4.1 has already proven itself as a top-tier reasoning and coding model; Opus 4.5 now arrives with lower pricing, better coding and agentic performance, and a new effort parameter that finally lets you dial in cost vs capability per request. This guide compares Claude Opus 4.5 vs 4.1 from a developer and product perspective so you can decide if migrating your application is worth the engineering effort and how to extract value from day one.
Claude Opus 4.5 vs 4.1: high-level overview
Both models sit at the top of Anthropic’s stack, but they now occupy slightly different roles.
| Feature | Claude Opus 4.5 | Claude Opus 4.1 |
|---|---|---|
| Release date | Nov 24, 2025[1] | Aug 5, 2025[2] |
| Claude API model ID | claude-opus-4-5-20251101[3] | claude-opus-4-1-20250805[3] |
| Pricing (API) | $5 / $25 per million input / output tokens[3] | $15 / $75 per million input / output tokens[3] |
| Context window | 200K tokens (64K max output)[3] | 200K tokens (32K max output)[3] |
| Knowledge cutoff / training cutoff | Reliable knowledge to Jan 2025; training data through Aug 2025[3] | Reliable knowledge to Jan 2025; training data through Mar 2025[3] |
| Effort parameter | Supported (beta, Opus 4.5 only)[4] | Not supported |
| Positioning | Best general model for coding, agents & computer use[1] | Exceptional reasoning model; upgrade over Opus 4[2] |
In other words: Opus 4.5 is strictly more capable, significantly cheaper, and more controllable than Opus 4.1. The real question is whether you need its new controls and benchmarks badly enough to justify migration work right now.

Key performance differences: coding, agents, and reasoning
Anthropic positions Opus 4.5 as “the best model in the world for coding, agents, and computer use”[1], while Opus 4.1 is described as an upgrade over Opus 4 for “agentic tasks, real-world coding, and reasoning”[2]. The delta is visible in benchmarks and real-world feedback.
Coding and SWE-bench
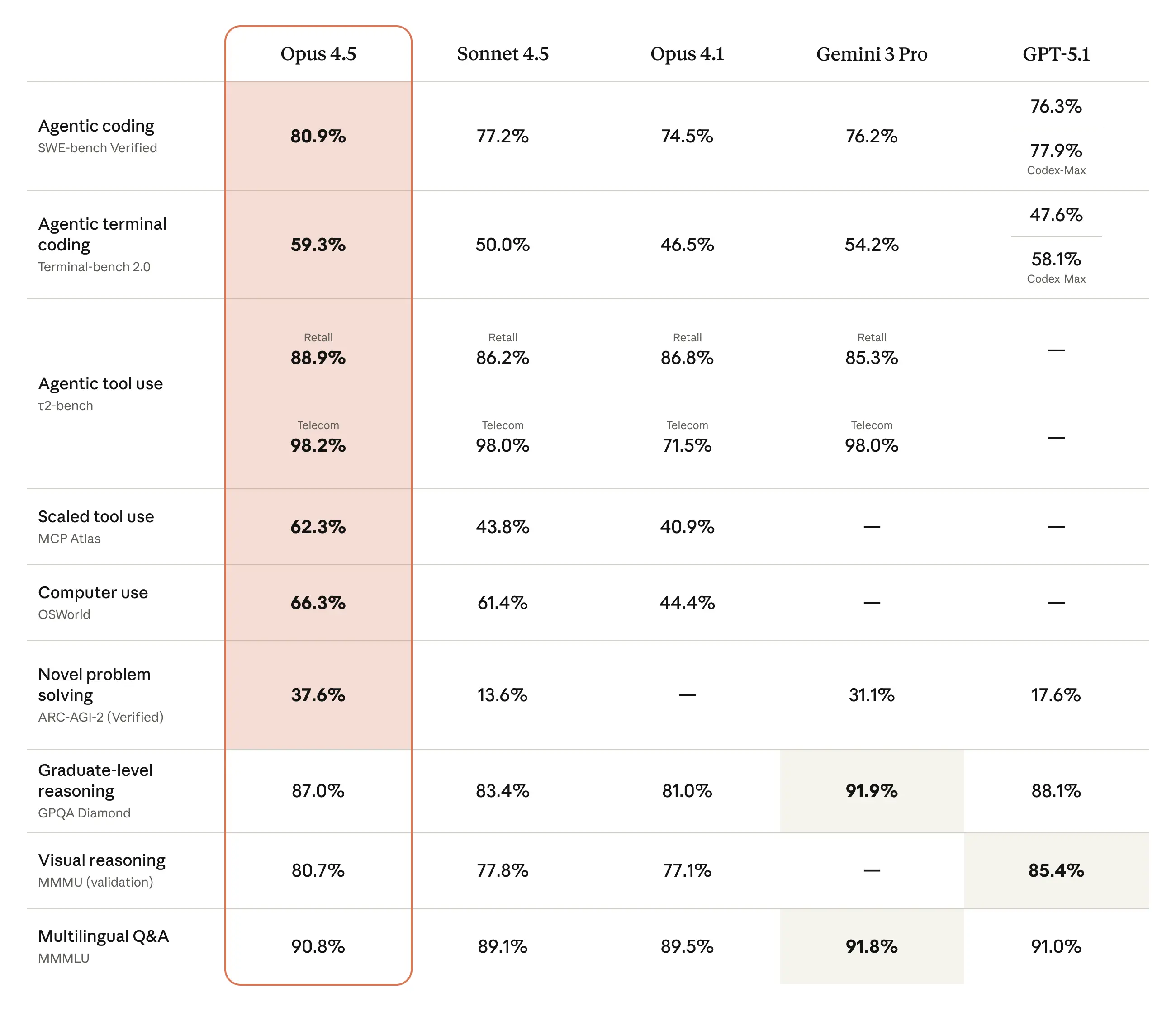
Opus 4.1 pushed Claude’s SWE-bench Verified score to 74.5%[2], using a simple bash + file edit scaffold. Opus 4.5 goes further, becoming state-of-the-art on real-world software engineering tests like SWE-bench Verified and internal Anthropic coding exams[1]. Anthropic reports:
- On SWE-bench Verified, Opus 4.5 matches or beats Sonnet 4.5 while using far fewer tokens when effort is tuned.
- On Anthropic’s internal performance engineering take‑home, Opus 4.5 scored higher than any human candidate within a 2‑hour limit[1].
- Partners like GitHub report 50–75% reductions in tool-calling and build/lint errors with Opus 4.5, and fewer iterations to finish complex tasks[1].
If your current Opus 4.1 integration focuses on multi-file refactors, bug fixing, or large repo comprehension, Opus 4.5 will typically:
- Solve more tasks end-to-end,
- Need fewer clarification turns, and
- Spend fewer tokens to reach the same or better outcome (especially at
mediumeffort).
Agentic behavior and tool use
Both Opus 4.1 and 4.5 are hybrid reasoning models with extended thinking and advanced tool use. The difference is how deeply they can reason over long horizons and coordinate multiple tools and subagents.
- On τ2-bench–style tasks (multi-step agents acting as airline or retail support), Anthropic reports that Opus 4.5 finds creative, policy-respecting solutions that benchmarks didn’t even anticipate[1].
- On long-horizon terminal workflows (Terminal Bench), Opus 4.5 shows a measurable improvement over Sonnet 4.5, with fewer dead-ends and more robust plan execution[1].
- Anthropic’s own deep-research evals show around a 15‑point performance boost for Opus 4.5 when combining effort control, context editing, and advanced tools[1].
Practically, if you’re building agents (support bots, coding copilots, research assistants), Opus 4.5 is better at:
- Maintaining and updating internal plans,
- Orchestrating multiple tools and subagents, and
- Recovering from mistakes without human intervention.
Safety and robustness
Opus 4.5 continues Anthropic’s “most aligned yet” trend. Its system card and launch blog emphasize:
- Lower “concerning behavior” scores across misalignment evaluations[5],
- Improved robustness to strong prompt-injection attacks (evaluated by Gray Swan)[1],
- More conservative handling of high-risk instructions while still being helpful.
For regulated industries or security-sensitive workflows (e.g., finance, healthcare, enterprise IT automation), Opus 4.5’s safety and injection resilience add a strong argument for upgrading.
The new effort parameter: dynamic cost vs capability control
The single biggest API-level change when comparing Claude Opus 4.5 vs 4.1 is the introduction of the effort parameter. This is available only on Opus 4.5 and currently in beta[4].
What effort controls
Effort lets you control how “eager” Claude is to spend tokens across the entire response:
- Text responses and explanations,
- Tool calls and tool arguments,
- Extended thinking tokens (when enabled).
From the official docs[4]:
“The effort parameter allows you to control how eager Claude is about spending tokens … trading off between response thoroughness and token efficiency, all with a single model.”
Claude Docs – Effort
Supported levels:
| Effort level | Behavior | Typical use case |
|---|---|---|
high | Maximum capability; uses as many tokens as needed. Same as omitting the parameter. | Hard reasoning problems, complex agents, deep code refactors. |
medium | Balanced capability and token savings. | General-purpose agents and copilots, default for most apps. |
low | Most efficient; aggressively conserves tokens. | Simple tasks, subagents, classification, routing, high-volume calls. |
How to use effort in the Claude API
Effort is currently a beta feature for Opus 4.5. You must:
- Use an Opus 4.5 model ID (
claude-opus-4-5-20251101), and - Include the beta header
effort-2025-11-24.
import anthropic
client = anthropic.Anthropic()
response = client.beta.messages.create(
model="claude-opus-4-5-20251101",
betas=["effort-2025-11-24"],
max_tokens=4096,
messages=[{
"role": "user",
"content": "Summarize this 50-page spec for PMs and engineers."
}],
output_config={
"effort": "medium" # "high", "medium", or "low"
}
)
print(response.content[0].text)Anthropic’s launch post gives a concrete sense of the trade-offs[1]:
- At medium effort, Opus 4.5 matches Sonnet 4.5’s SWE‑bench score using 76% fewer output tokens.
- At high effort, it exceeds Sonnet 4.5 by 4.3 points on SWE‑bench while still using 48% fewer tokens.
Because effort governs tool calls and thinking as well as final text, it’s far more powerful than “just shorten the answer.” Opus 4.1 gives you none of this fine-grained cost control.
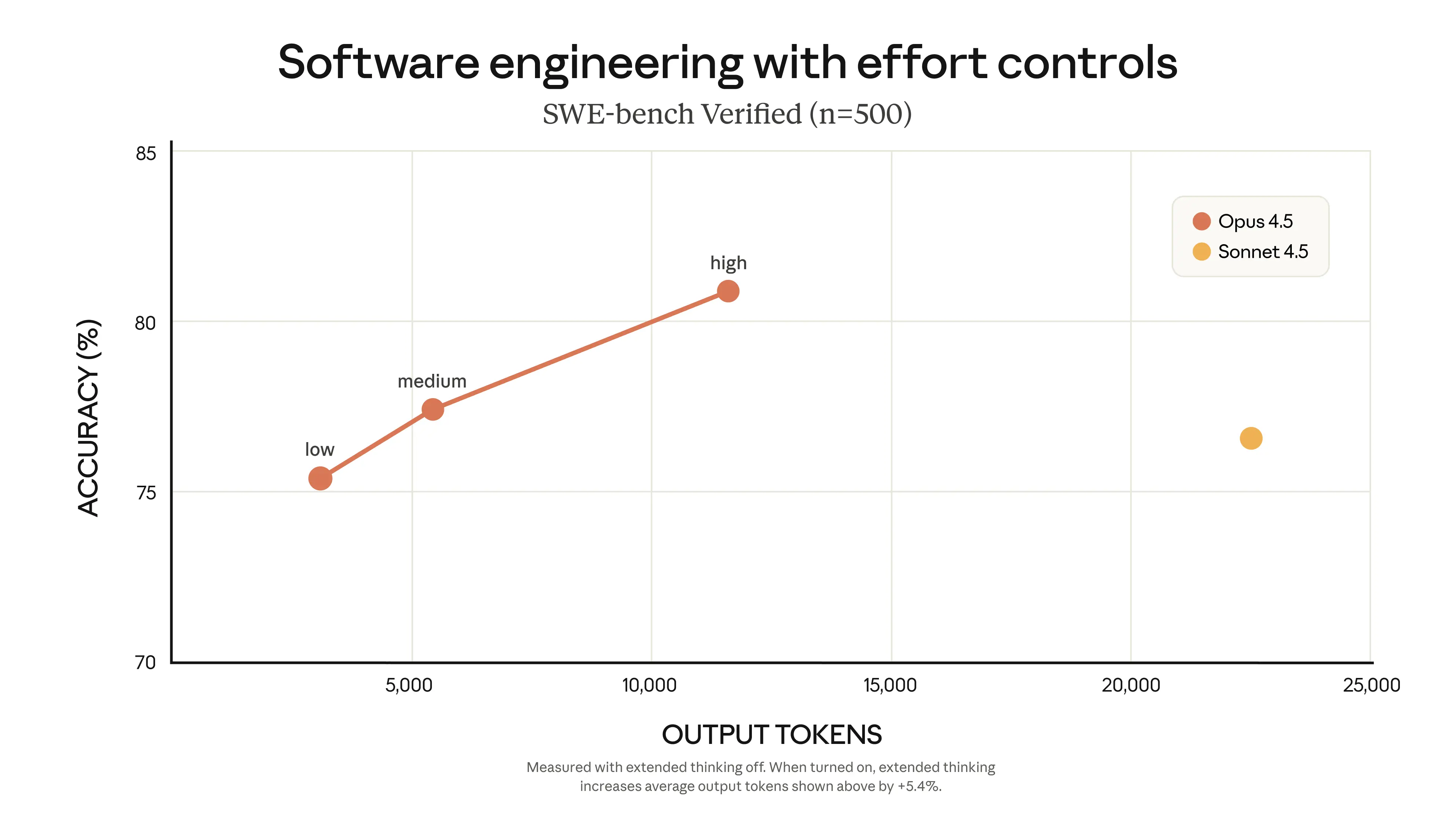
When to dial effort up or down
- Use high for: root-cause debugging in large monorepos, multi-step financial analysis, non-trivial research and planning, or any task where missing edge cases is unacceptable.
- Use medium for: day-to-day copilot behavior, support agents, and most production flows where you want strong reasoning but need predictable spend.
- Use low for: routing, summarization of already-clean inputs, email drafting, and subagents that feed into a higher-effort coordinator.
None of this exists in Opus 4.1. If you’re hitting budget or TPM limits on 4.1 today, migrating just to get effort control and lower base pricing is usually worth it.
API, pricing, and migration considerations
Cost and rate limits
According to Anthropic’s model overview[3], Opus 4.5 is dramatically cheaper than Opus 4.1 on a per-token basis:
- Opus 4.5: $5 (input) / $25 (output) per million tokens.
- Opus 4.1: $15 (input) / $75 (output) per million tokens.
Combine those unit prices with the fact that Opus 4.5 can achieve similar or better results with substantially fewer tokens (especially under tuned effort), and in most real-world workloads you’ll see:
- Lower absolute cost for the same workload, and
- More requests within your existing budget or quota.
For organizations previously limiting Opus 4.1 to high-value flows due to cost, Opus 4.5 essentially opens up “Opus everywhere” as a viable option.
API changes: how “drop‑in” is the upgrade?
Opus 4.1 was explicitly marketed as a drop‑in replacement for Opus 4[2]. Opus 4.5, by contrast, changes pricing and adds capabilities but keeps the same Claude 4 messages API design[3]. Migration typically involves:
- Updating the
modelID fromclaude-opus-4-1-20250805toclaude-opus-4-5-20251101, - Optionally introducing the
betasheader andoutput_config.effort, and - Re-running your regression tests (especially if you rely on exact string formatting).
Anthropic’s broader “Migrating to Claude 4.5” guide is aimed primarily at 3.x users, but the same principles apply from 4.1 to 4.5[6]: prefer fixed snapshot IDs for production, and maintain a small A/B test harness to watch for behavior changes.
Backward-compatibility and output stability
Neither Opus 4.1 nor 4.5 is guaranteed to be drop‑in identical for tasks that depend on exact wording, whitespace, or markup. Anthropic notes that 4.5 also includes better tool parameter handling and formatting preservation in tool calls[7], which is usually an upgrade but can surface hidden assumptions in your parser.
Before fully switching:
- Clone your production prompts and fixtures.
- Run them against both Opus 4.1 and 4.5.
- Diff outputs for:
- JSON schema adherence or structured outputs,
- Tool call JSON shapes, and
- Any user-facing tone that might need retuning.
Should you upgrade from Claude Opus 4.1 to 4.5?
Whether the jump from Claude Opus 4.1 to 4.5 is “worth it” depends on how you use 4.1 today. Below are common scenarios and recommendations.
Scenario 1: heavy coding & refactoring workloads
If your app powers IDE copilots, batch refactors, or automated code migration, Opus 4.5 is almost always a win:
- Higher success rates on complex, multi-file tasks.
- Fewer tool-calling and build errors in partner benchmarks[1].
- Substantial cost savings from both cheaper tokens and better token efficiency.
Recommendation: Upgrade and A/B test for a short period, then roll out broadly. Use high effort for core refactor flows and medium for lighter assistive tasks.
Scenario 2: long-horizon agents and complex workflows
For research agents, customer support bots, office automation, or multi-agent systems, Opus 4.5’s improvements in planning, subagent coordination, and prompt-injection resistance matter:
- Better performance on agentic benchmarks and deep research tasks[1].
- Effort + context editing + advanced tools combine to push performance up ~15 points on Anthropic’s browse-based research eval[1].
- Safety and injection resilience are stronger, which directly impacts production risk.
Recommendation: Upgrade your main coordinator agent to Opus 4.5 with high or medium effort and consider running cheaper subagents (also 4.5) at low effort to save spend while improving overall system robustness.
Scenario 3: cost-sensitive SaaS products
If 4.1’s $15 / $75 pricing has forced you to:
- Strictly cap feature usage,
- Reserve Opus only for “pro” tiers, or
- Mix in cheaper models with custom routing logic,
then Opus 4.5’s combination of lower base prices and effort-based throttling is strategically important.
Recommendation:
- Switch core flows to 4.5 at
mediumeffort, - Use
loweffort for low-stakes, high-volume actions, and - Consider upgrading lower tiers from Sonnet to Opus 4.5 selectively, since per-request cost may now be comparable.
Scenario 4: highly stable, regulated workflows
In regulated workflows (compliance checks, legal triage, medical documentation), output stability and revalidation costs can dominate pure model performance. Opus 4.1 is already strong here, and any model change triggers review.
However, Opus 4.5 offers:
- Better safety and alignment scores[5],
- Stronger protection against sophisticated prompt injection[1], and
- Lower cost, which matters at scale.
Recommendation: Plan a deliberate migration: mirror traffic to 4.5, run compliance and safety evaluations, and switch once you have internal sign-off. The long‑term risk profile is likely better on 4.5 than 4.1.
When it might be reasonable to stay on 4.1 (for now)
- Your team has just migrated from Sonnet 4.5 or Opus 4 to Opus 4.1 and is still stabilizing.
- You rely heavily on fine‑tuned parsing of 4.1’s exact outputs and don’t yet have bandwidth for regression testing.
- Your current workloads are light enough that 4.1’s cost doesn’t hurt, and you don’t yet need effort-based control.
Even in these cases, it’s wise to set up a small test harness against Opus 4.5 so you’re ready when 4.1 eventually becomes legacy.
Practical migration strategy: leveraging new features immediately
Once you decide to move from Claude Opus 4.1 to 4.5, a pragmatic rollout can keep risk low and ROI high.
- Switch a single service or feature flag to 4.5
Start with one microservice (e.g., code refactoring or summarization). Update the model ID and keep all prompts unchanged. - Introduce effort configuration
Expose effort as a per-endpoint or per‑task setting in your config, for example:effort: high | medium | lowin your YAML/env, then pass it throughoutput_configonly for Opus 4.5 calls. - Measure three dimensions
Track: (a) task success rate / quality, (b) average tokens per task, and (c) latency. Compare against 4.1 baselines. - Roll out to more workloads
Once metrics are favorable, extend 4.5 to more endpoints. Usehigheffort where quality is critical, and gradually experiment withmediumandlowto find safe savings. - Decommission 4.1 paths
When you’re confident in stability and cost benefits, simplify your stack by removing 4.1-specific routing and tests.
Because Opus 4.5 is available across Anthropic’s API, Bedrock, and Vertex AI[1], multi-cloud users can follow the same high-level plan in each environment, just swapping provider-specific model IDs.
Conclusion: is Opus 4.5 worth the upgrade?
Comparing Claude Opus 4.5 vs 4.1, the pattern is clear: 4.5 is better, cheaper, and more controllable for almost every serious developer use case. It delivers higher coding and agentic performance, a larger max output window, better safety and injection robustness, and the new effort parameter that turns cost vs capability into a tunable API-level decision instead of a model-swap problem.
If you’re running production agents, IDE copilots, or complex automation on Opus 4.1 today, migrating to 4.5 is usually justified within a single iteration cycle, especially once you factor in reduced token spend. The main exceptions are ultra-stable, compliance-heavy workflows where any model change entails heavy revalidation; even there, Opus 4.5 is the more future-proof target and worth piloting now.
The fastest path forward is simple: mirror a slice of your current Opus 4.1 traffic to Opus 4.5, turn on effort at medium, and compare cost and quality. For most teams, that small experiment will answer the upgrade question decisively.


